Source Code!
https://github.com/england2/aws-demo/
Overview
The Agent Conductor is responsible for scheduling and managing agents in reaction to tickets and AWS platform incidents.
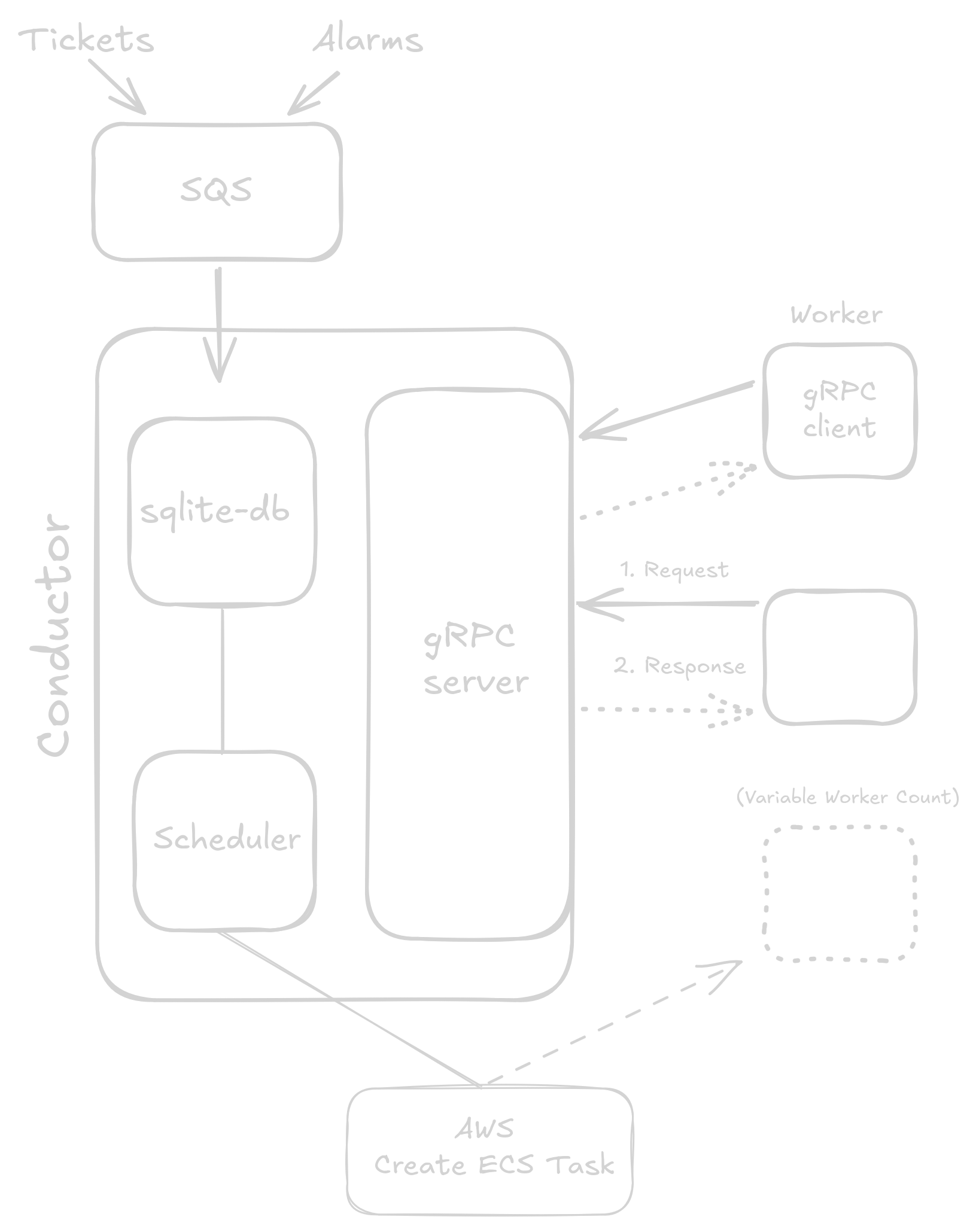
At a high level, here is how this project works:
- Tickets and CloudWatch alarms are pushed to an SQS queue which the conductor polls for new work
- When the conductor gets new SQS messages, it passes the messages to the scheduler routine:
- The scheduler places all tickets and incident alarms into an internal database
- The scheduler uses a stable database to determine if a job has already been spawned for a ticket or an ongoing incident
- The scheduler routine returns to main with a decision whether or not to spawn an agent
- The conductor interprets the decision and, if necessary, spawns a worker in a Fargate container
- The worker’s main binary talks to the conductor via gRPC, waiting for task files that determine its job
- The conductor sends the worker its task files
- The worker starts a Codex agent, which does the requested work. After the agent finishes, the worker binary submits changes to GitHub and reports back to the conductor before exiting, ending the job and the Fargate instance.
Database Scheduling System
The conductor is responsible for deciding when to schedule an agent to run, in addition to what type of agent it will be, e.g., an incident response or a ticket worker.
So far, there are two types of scheduling that the conductor can perform, which are ticket scheduling and incident scheduling, which spawn the two worker types above.
Here is how both work.
Ticket scheduling
- The conductor receives a ticket from SQS, sourced from something like Jira.
- The scheduler stores the ticket in the database.
- If the ticket has not already been scheduled, the scheduler tells main to spawn one agent for it.
- If the ticket has been scheduled already, then no agent spawns.
Ticket scheduling is simpler than incident scheduling. Basically, the only point of the database here is to prevent repeating work.
Incident scheduling
Incident scheduling relates to CloudWatch alarms, such as high CPU alerts, error rates, cost anomalies, etc. We’re trying to spawn agents in reaction to AWS platform events, so there is slightly more logic involved than in ticket scheduling.
- The conductor receives a CloudWatch alarm message from SQS.
- The scheduler stores the alarm in the database.
- The scheduler then determines if the alarm is “chained” to other alarms. Alarms are chained if they are within one hour of another alarm with the same AWS account number.
This way, a single incident which produces many alarms will only spawn a single worker to investigate per account.
Achieving Program Durability via Scheduling on a Database
The above describes simple scheduling logic that could easily be done in program memory without a database.
Of course, the issue with this is that program memory dies when the program dies.
The database is useful because it lets the conductor remember what has already been scheduled. If the conductor restarts, it can continue its chaining logic where it left off just based on the database.
Improved Program Testability With Database Scheduling
Deciding when to spawn an agent and with what context, permissions, repos, prompts, etc. to provide the agent with is (or will be) a very important part of the program.
It’s important to get scheduling right, as badly scheduled agents will likely produce many penalties:
- Wasting engineer hours on reviewing repeated diffs (happens if we spawn too many agents per incident)
- Wasting engineer hours on reviewing broken/failed jobs (agents with weak context and incomplete execution environments)
- Avoidable agent merge issues (repo-claiming subsystem doesn’t work; too many agents per incident)
- Wasting money on Fargate instances (too many agents)
- Delayed execution of legitimate agent work (too many agents)
Basing scheduling decisions on a database means that we can load many scenarios into different test databases and see exactly what scheduling and spawn-context decisions the scheduler would make in different situations.
For example, what scheduling decisions will be made if 100 alarms trigger in one hour across many accounts? Or if the system somehow gets sent 10 tickets per second? Will the conductor allocate agents to the correct repositories, will it choose to solve tickets instead of reacting to the incident, will it encounter an obscure logic error and not schedule anything at all, will it spawn agents that are at risk of encountering merge issues?
These are all questions that can be easily answered when the correct test data is written, because the scheduler mostly looks at its internal database to schedule agents and not ephemeral, in-memory data structures.
Notably, one could use old, existing system data to test scheduling in addition to test data generated by scripts.
This being said, current scheduling logic is relatively simple, and if the scheduler didn’t rely on a database it could absolutely still be tested. But scheduling based on a database makes testing easier, which is important in case more complex scheduling behavior were needed.
Note: Incident Scheduling vs Ticket Scheduling in Early Versions
The above penalties and potential complexity wouldn’t occur if the conductor only solved tickets instead of also reacting to alarms.
For this reason, I’m interested in getting a rock-solid base program with well-tested subsystems (e.g., git/platform permissions, multi-AWS account complexity sorted out, repo-claiming, etc.) before trying to implement potentially complex incident-based scheduling that may rely on OTel, CloudWatch, and other data to make decisions.
In short, the v1 production conductor would only respond to tickets. This would allow time to iron out the system’s fundamentals while it still has predictable ticket-only scheduling and the stakes/penalties are generally lower.
Finally, while the current scheduler may seem too simple to necessitate robust testing, note that the scheduling step could expand into these subsystems or features:
- A repo-claiming system to prevent two agents from simultaneously working on the same codebase, thus preventing easily avoided merge conflicts.
- A dev-container system to ensure that the agent will run its main worker binary on the best possible execution environment.
- A context-reuse system to allow agents to reuse their old memories of familiar codebases rather than wasting many tokens getting their bearings on every spawn.
- A job retry system.
- A multi-account scheduler that could allow agents to diagnose and inspect incidents regarding multi-AWS-account connectivity and logic (i.e deploying a single agent to investigate two or more separate repositories whose source code expresses network connections between one another).
Conductor Deployment Process
We want to be able to update the conductor while it’s deployed without orphaning the workers it manages.
In other words, we can’t kill the server and restart it while there are still active jobs.
To solve this, the deployment pipeline and conductor do two things:
- After the pipeline activates, the conductor will stop accepting new jobs.
- The conductor does not shut down until the agents it is managing are finished with their work.
We achieve this using a simple system described below.
Conductor Safe Shutdown Gate
The main logic units of the conductor all run in goroutines, which on their own do not prevent the program from returning from main and exiting.
The conductor process stays open by maintaining a shutdown gate, which is just a for loop with a few conditionals.
The conductor watches a file called IS_CONDUCTOR_SHUTTING_DOWN which starts as false. When we deploy a new version of a conductor, the deployment process flips this file to true, and the conductor will not schedule new jobs, allowing messages to safely pool in the SQS queue.
After the file is set to true, the shutdown gate counts the number of active workers, and the program exits when it reaches zero. Before exiting, the conductor writes the file CONDUCTOR_READY_FOR_SAFE_SHUTDOWN, informing the deploy script that the shutdown gate has concluded and a new version can be deployed.
Miscellaneous Thoughts, Improvements, Etc.
This section holds some thoughts not related to the primary writeup.
Agents Improve From Existing DevOps Practices Such as Vagrant
Agents benefit from living in a runtime container that has all of the tools they need to work. For instance, agents won’t be able to do their job if they lack
rustcwhile working on Rust code. Additionally, they benefit from having the exact same tool versions that devs have, as well as miscellaneous scripts.Therefore, if each environment/repo the agent may alter uses tools like Vagrant to normalize developer workflows, the scheduler could consume a map relating AWS accounts to their associated dev containers.
Instead of running an agent in a general purpose container, a step could be performed to drop the worker binary onto an existing developer environment container, serving as the agent’s execution environment.
Areas of Improvement + Possible Features (Non-exhaustive)
- Reduce complexity and LoC by using S3 to transfer files instead of chunking files over gRPC.
- Use ECS to deploy containers onto stable EC2 instances (targeting the conductor host server and test application servers) rather than using makeshift SSM-based pipelines.
- Better test coverage across the codebase.
- Conductor can handle orphaned workers; workers can handle being orphaned.
- Conductor uses the AWS SDK to poll and kill the Fargate instance of workers if the worker’s gRPC client can’t send a handshake.
- General refactoring.
- Repo-claiming system where workers are blocked on active repositories; possibly pull unmerged PRs when they start their work after being unblocked.
- (OSS-related) Make a bootstrap Python program to seed Terraform/other code areas with user-specific configuration.